
The use case
As a tinkerer, I really like putting things together, especially if they go on working on their own like little automatons. But when there is an actual need for something that these automatons can cover, that’s even better!

In this case, after changing some parts of our configuration and monitoring tools arsenal a few years ago, the capability of storing and looking up mac address history for our network switches was significantly diminished. We could no longer tell if a certain mac address was present in the network 3 months ago (and where) or look at the history for a specific switch and be able to tell that for specific ports, nothing had been active on them for the last 6 months so we could re-assign them.
We got used to doing without it for a while, but after some time, while in the process of learning new tools and acquiring new skills, I thought “How cool it would be if we could actually build what is missing here ourselves?”.
How it came to be – getting to know InfluxDB
Getting to know InfluxDB and Time Series Databases started like any journey. With small steps.
The first step was migrating SNMP monitoring from MRTG to a Time Series Infrastructure (TIG), which I posted about twice (Part-1 & Part-2).
The second was using Time Series DB to store concurrent VPN users collected with Python code from Checkpoint Firewalls, which I also posted here .
Then I wanted to migrate network latency monitoring from Smokeping to Telegraf as a collector on Raspberry Pis and store to Time Series again (TIG again), only this time it didn’t seem necessary to post a blog entry about it, as it wasn’t exactly new to everyone, besides using docker and docker-compose and the PIs only as collectors not docker hosts. For example, you can read Michael’s post about deploying TIG on RPi here. After asking in Influx Data slack about which InfluxDB version to pick, Michael Hall suggested using v.2.x.
So I decided to go ahead and try version 2.x. I have to say that I am still a novice user where InfluxDB is concerned. So far I had learned just enough to do what I want with InfluxDB v.1.x and the respective python client (I believe the phrase goes “I know enough to be dangerous”..).

It’s true that at that point, the move from InfluxDB v.1.x to v.2.x and from iQL to Flux for InfluxDB query language, made a lot of people nervous, especially network engineers doubling in automation, like me. Some were so frustrated that they decided to find a different Time Series DB to use for their projects. Others, just resorted to using a compatibility layer offered by Influx Data for accessing a DB on InfluxDB v.2.x with v.1.x compatibility.
After using InfluxDB time after time in my projects, I wanted to stay on the same train. I also didn’t want to give up. So I tried with reading, learning & getting the pieces together and barely made it. There were very few posts around for deploying InfluxDB v2.x on Docker with docker-compose at the time.
Essentially there was just one complete post about it, by Anais Dotis-Georgiou from Influx Data. It soon became obvious to me that the logic behind the post was not exactly a detailed how-to, listing one step after another but rather an introduction, a starting point on how to address each task.
After a few attempts I got to a working instance and I did manage to develop the latency monitoring solution along with Telegraf collectors on the RPis. I started with ICMP probes and meant to go on with DNS, Https and any service I was already monitoring with Smokeping. But as far as the infrastructure was concerned I didn’t feel I had grasped exactly the setup procedure. It didn’t feel as IaC, as I had to launch the containers for the first time and then do a few setup tasks on them before I could use them. That could not work in the long run.
As it happens, I got another chance. We were at the moment locked tight in a project leading to a migration to an SD-Access Network. So when I saw the need for a solution to gather mac address history on the current network to help with the migration processes, I knew it was time to try to get a better grasp and use InfluxDB v.2.x for storage.
Components – Architecture
The project, as it formed in my mind, had 4 parts:
- The inventory for network devices
- The collector for the data
- The TSDB to store it
- The python client to move the data to the TSDB.
Inventory – Nautobot
We were already using Nautobot as a DCIM – IPAM (Datacenter Infrastructure Management – IP Address Management) platform enriched with automation capabilities. It’s deployed on Docker using docker-compose, you can read about it here. Using Nautobot to cover this need was a natural step, as it already contained the data we wanted for where to connect and how and we regularly spend the time and effort to keep it up to date anyway, so no additional maintenance cost compared to keeping a separate Nornir inventory in place.
Collector
Nornir
Nornir (& Nornir on Github) is a Python framework allowing for simultaneous execution of tasks either for gathering data or configuring devices or whatever anyone would consider a task towards a device accessible via the network. It’s well known for it’s speed and efficiency in such use cases in the field of network automation.
Nornir only provides the framework, not the connection. The connection provider for each switch is Netmiko in this case, deployed as a Nornir plugin. There are other options available (e.g. Scrapli) but Netmiko does just fine. It is coupled with NTC-templates/ text-fsm based parsers to break down responses to structured data, so that they can be used further down the path for whatever task is necessary.
I already had some experience with Nornir on various projects (e.g. https://github.com/itheodoridis/nornirchangewandes) and my workmate has also been using it as well for every day tasks with various scripts she has written herself (e.g. https://github.com/kdardoufa/Nornir_Check_Route). So again, easy choice.
I decided to test the script on a virtual environment but after that create a docker container based deployment that would run periodically for collecting the info. I used python 3.9.16 for the virtual environment and the default version of python 3.10 is used in the Ubuntu 22.04 docker image that runs the code periodically.
Nornir + Nautobot
Nornir requires an inventory of devices to draw targets (and respective data) from. Some time ago I discovered that there was Nornir plugin that could draw inventory data from a Nautobot instance, so naturally I thought that combining the two was well worth the effort, as I would not have to keep updating a separate inventory of devices just for Nornir, but could instead rely on Nautobot and even more, I could use Nautobot’s filters, tags, attributes and categories to choose the targets for my scripts, or exclude others.
I first tested the inventory plugin with my Nautobot instances. After succeeding in accessing the inventory data, I went after my main target, writing tasks to get the mac addresses contained at each network access switch’s mac address table at any given time, or, to be more precise, specific points in time, spaced by regular intervals.
As mac addresses were gathered, it made sense to gather all relevant information as well at the same time, such as the switch ip address and port that the mac address appeared, but also to which ip address and hostname it could be resolved with ARP and DNS, if such information was available.
Code philosophy – DRY principle
I could create a single script that would contain the whole code. However I wanted to write code that could be reused as much as possible, as it wasn’t our first project and certainly would not be the last. So I broke down each of the processes as much as I could, enforcing the DRY principle. Right now very little part of the code is repeated between parts of the flow. The code makes one distinction: there are two separate flows previewed depending on whether one needs to run a single command, or multiple commands. To accommodate that, functions names are often used as parameters in other functions that determine the actual flow.
Data filtering
The “show mac address-table” command in Cisco Switches produces a table in the CLI output, where all mac addresses present in the switch CAM are displayed. Those include mac addresses used by the Switch (marked with ‘CPU’ in the ‘destination port’ column) and some that are learned via ports where other switches are connected.

Those switches can either be Core switches or adjacent peer access switches. If we want to collect host mac addresses we need to associate them with their locally significant information which is relevant only for the switches where the hosts are directly connected to. So we need to ignore those two categories of mac addresses, when we collect the list of mac addresses from every CAM table.
Essentially this means running at least one more command to find out which ports are connected to other switches (“show cdp neighbors detail”) and filtering those entries out, while also filtering out entries with ‘CPU’ in the ‘destination port’ field.
Fast code walk-through
The code is available in this repo, (still completing with the detailed description for every function and file, but the code is working). Every piece of sensitive information has been replaced with generic values. There are previsions to allow for the code to be run with debug info on the console and/or logging (on file). As the code was meant to be run periodically on a container, in that cases those “flags” are defined as ‘False’.
The code starts by defining the inventory for Nornir, by providing Nautobot credentials and initializing the inventory. The inventory values that are mapped to Nautobot device attributes are passed as parameters. That way the code can be reused to run tasks on other groups of devices. In this case it’s run against all switches in the access network.
In the next phase, the collection is separated in two stages. As there are still some switches left that support only telnet for remote management, an appropriate filter (also passed as parameter) is used to create two groups:
- The switches that support ssh for remote management
- The switches that support telnet only for remote management
Depending on the connection protocol supported, the nornir run parameters need to be adjusted as the older switches are more prone to connection errors. One such adjustment for instance, is the delay inserted for the connection attempts. Those options are passed to the connection provider to each switch, in this case Netmiko. At each task run the pieces of info collected are mac address, switch port, switch ip address, switch name and switch location (site code).
After each group run the results are added to a list of mac address entries, and the final list is passed to the next part for processing: matching mac addresses with ip addresses based on IP arp information.
The IP arp collection process uses the same skeleton of functions, however this time the inventory is created with different parameters so that the L3 switches per site are selected as targets. The flow is also adjusted to match a single command : ‘show ip arp’
After the results are used to enhance mac address info collected in the previous step with host ip address information, the code attempts to resolve ip addresses to hostnames and results are enriched further with this piece of information.
Below is the main script which is the part of the code that does the functions calls for each step and then writes the points in the DB.
#!/usr/bin/env python
from nornir_nauto_noc_utils import get_the_macs_addresses,get_the_arps,enrich_node_mac_data
from noc_net_utils import node_resolve
from nautobot_credentials import nautobot_url, nautobot_token
from influxdb_client.client.write_api import SYNCHRONOUS
from influxdb_credentials import bucket,org,token,url
from influxdb_client import InfluxDBClient, Point, WriteOptions
import time
import ipdb
def main():
#TODO - run the logger in the main function so the functions can be transfered to a separate file (library)
filter_param_dict = {"status": "active", "site" : ["site1", "site2", "site3"], "role" : "ac-access-switch",
"has_primary_ip": True}
mac_list = get_the_macs_addresses(nautobot_url,nautobot_token,filter_param_dict,SAVE_RESULTS=False,DEBUG_DATA=False,DATA_LOGGING=False)
if mac_list == None:
print("no mac addresses were collected")
return()
filter_param_dict = {"status": "active", "site" : ["site1", "site2", "site3"], "role" : "ac-distribution-switch",
"has_primary_ip": True}
arp_list = get_the_arps(nautobot_url,nautobot_token,filter_param_dict,SAVE_RESULTS=False,DEBUG_DATA=False,DATA_LOGGING=True)
if arp_list == None:
print("no arp entries were collected")
return()
resolved_list=node_resolve(arp_list)
final_list = enrich_node_mac_data(resolved_list,mac_list,SAVE_RESULTS=True,DEBUG_DATA=False,DATA_LOGGING=True)
if final_list == None:
print("no resolved entries were collected")
#ipdb.set_trace()
client = InfluxDBClient(
url=url,
token=token,
org=org,
verify_ssl=False
)
write_api = client.write_api(write_options=SYNCHRONOUS)
timestr = str(time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime()))
for record in final_list:
#p = influxdb_client.Point("mac-address-access-network-attiki").tag("mac-address", record['mac_address']).field("temperature", 25.3)
p = Point("mac-address-access-network"
).tag("switch_address",record["switch_address"]
).tag("switch_name",record["switch_name"]
).tag("port",record["port"]
).tag("mac-address",record['mac_address']
).tag("host_ip",record["host_ip"]
).tag("host_name",record["host_name"]
).tag("vlan",record["vlan"]
).field("switch_location",record["switch_location"]
).time(timestr)
write_api.write(bucket=bucket, org=org, record=p)
client.close()
return()
if __name__ == "__main__":
main()
Here are some links to get more insight about the python client for InfluxDB v.2.x
- https://influxdb-client.readthedocs.io/en/stable/usage.html#synchronous-client
- https://www.influxdata.com/blog/influxdb-python-client-library-deep-dive-writeapi/
- https://github.com/influxdata/influxdb-client-python
- https://docs.influxdata.com/influxdb/v2.6/api-guide/client-libraries/python/
- https://docs.influxdata.com/influxdb/v2.6/reference/syntax/line-protocol/
Next steps
There is still room for improvement of course. One thing to consider is replacing the logic that corrects the interface names with the use of the net-utils package for canonical interface names (see “Quick Hits” subtitle in the blog post linked) when doing the comparison. Another thing that will probably change in the future is publishing the code as one or more python packages to allow for easier integration in other places (for example in nautobot jobs) but also to facilitate sharing with the community.
Setting up the TSDB infrastructure
As mentioned I had chose to use InfluxDB v.2.x but decided to do it right this time. The usual way to get insight/help with InfluxDB is to use their Influx Community Slack workspace and the InfluxDB-v2 channel in this case. As Influx Days 2022 was coming up, the annual InfluxDB Online conference, I thought it would be great to watch and get myself up-to-date but also use the momentum to get more insight on what I wanted to do and what the weak points were in my setup procedure. If you want to catch up with what was presented in the conference, here is the direct link to the Youtube list for the event. I particularly liked Anais’s presentation “Becoming a Flux pro” which was very informative on such a controversial subject for network engineers: Understanding how Flux works. You can watch it below (or head to Youtube and watch it there):
Perhaps the most interesting part for me is where she describes how “input != output” for InfluxDBv2, a common misconception among engineers who are just starting to get to know InfluxDBv2.x, how Flux is more than just a query language and the importance of using the InfluxDB GUI (on InfluxDB Cloud or on-premise OSS version ) to get acquainted with Flux instead of trying to build queries on a separate visualization platform, for example Grafana. All solid insight and advice that helped a lot.
Major Challenges
When deploying InfluxDB on Docker, if you don’t provide any config parameters you can still get a container up and running but it needs a little more effort to get started with the DB , which can be completed via the GUI. For example in this kind of process with a similar set of commands you can get a copy of the default config by downloading the image, creating a container and then generate and copy the config on the docker host (in this case the container is deleted right after):
docker run --rm influxdb:latest influxd print-config > config.ymlHowever there are a few problems with this approach:
- Every config parameter is defined only in the container. If you delete the container to start again, every config parameter is gone. The same goes for data, unless a volume is defined for it.
- If you define enough docker config parameters when you create the container, you may get a more sustainable environment, for example a persistent config file on an external volume and persistent data on a named volume.
- Naturally defining those parameters in a docker-compose file is better as it’s a better suited yaml based format that makes it easy to define every parameter in detail, without resorting to long one-liners in the linux shell or bash scripts.
- However with just the minimum config parameters defined, you still get
- InfluxDB that needs initialization before it can be used and
- only http support for both the GUI and the connection to the DB.
- An additional but smaller challenge was finding out what the exact composition of services was for the docker containers for InfluxDB.
Resolution
Anais’s blog post, as already mentioned was a big help in understanding what was needed in my case. There was also a reference for a respective github repo. However the biggest help came from Anais herself in the InfluxDB slack at the time of Influx Days 2022, who verified that there was no need for a separate container for the InfluxDB CLI and from another website detailing what was not working for both the service composition and the auto initialization process. After resolving those issues using a little trial and error, I was able to fill in the blanks for the https support myself.
It should be noted that both the blog post and the github repo have been updated since. It should also be noted that in my use case, there is no real need for Telegraf. Anais’s post has you covered there too, in case you need to deploy it for collecting data (Telegraf is just amazing, there’s no end to its capabilities, check it out).
How to Deploy this
- Install Docker using this guide and docker-compose using this guide from Digital Ocean. I use Ubuntu Servers but you can either use another version of the guide from the drop down menu or find another guide with similar steps.
- Check this github repo and replicate file and directory structure. Make sure you have created your own ssl certificate for your server either self-signed or via a private or public CA. Name the files accordingly or edit the certificate names in the docker-compose and config files. No certificate files are included in the repo, only the references in the files.
- Edit the configuration files (influxv2.env and config.yml) and replace with your own settings and values. Be careful: the certificate is used for both the GUI and the access to the server via the client. This becomes obvious if you take note that tls and https cert file entries are the same in config.yml.
- You may want to create a user for influxdb in the docker host so that there is a reference to it in the running environment for influx in the container (the “user:” parameter):
sudo useradd -rs /bin/false influxdb
cd /opt/ti
sudo chown -R influxdb:influxdb influxdbv2/
sudo more /etc/passwd | grep influx- The last command will reveal the user id to fill in docker-compose (in this case 997:997). You may get away without using it.
- In docker-compose.yml, the influxdb image version is defined as 2.5.1. You can probably user a later version and everything should work with out changes. I believe the latest version at the moment is 2.6.1. You can choose between regular (Ubuntu based) or Alpine flavors. Anais’s post references the Alpine version which is lighter. It’s up to you.
- Deploy your server by running docker-compose up -d from the directory containing the docker-compose file.
- Connect to your influxdb server using https://<yourservername>:8086// with the credentials you already specified and enjoy InfluxDB v.2.x!
Here are the docker-compose.yml, influxv2.env and config.yml for quick reference while you are reading the post. At this time they are identical to the github repo files.
docker-compose.yml
version: '3.8'
services:
influxdb:
image: influxdb:2.5.1-alpine
container_name: influxdb
restart: unless-stopped
environment:
user: "997:997"
env_file:
- influxv2.env
volumes:
# Mount for influxdb data directory and configuration
- /opt/ti/influxdbv2/varlib:/var/lib/influxdb2
- /opt/ti/influxdbv2/config.yml:/etc/influxdb2/config.yml
- /opt/ti/influxdbv2/ssl/influxdb-selfsigned.crt:/etc/ssl/influxdb-selfsigned.crt
- /opt/ti/influxdbv2/ssl/influxdb-selfsigned.key:/etc/ssl/influxdb-selfsigned.key
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
ports:
- "8086:8086"
volumes:
influxdb2:influxv2.env
DOCKER_INFLUXDB_INIT_MODE=setup
DOCKER_INFLUXDB_INIT_USERNAME=adminusername
DOCKER_INFLUXDB_INIT_PASSWORD=adminpassword
DOCKER_INFLUXDB_INIT_ORG=Your organization name
DOCKER_INFLUXDB_INIT_BUCKET=your_bucket_name
DOCKER_INFLUXDB_INIT_ADMIN_TOKEN="yourinfluxdbtoken"
INFLUXD_TLS_CERT=/etc/ssl/influxdb-selfsigned.crt
INFLUXD_TLS_KEY=/etc/ssl/influxdb-selfsigned.key
HOST_PROC=/host/procconfig.yml
assets-path: ""
bolt-path: /var/lib/influxdb2/influxd.bolt
e2e-testing: false
engine-path: /var/lib/influxdb2/engine
feature-flags: {}
flux-log-enabled: false
hardening-enabled: false
http-bind-address: :8086
http-idle-timeout: 3m0s
http-read-header-timeout: 10s
http-read-timeout: 0s
http-write-timeout: 0s
influxql-max-select-buckets: 0
influxql-max-select-point: 0
influxql-max-select-series: 0
instance-id: ""
key-name: ""
log-level: info
metrics-disabled: false
nats-max-payload-bytes: 0
nats-port: 4222
no-tasks: false
pprof-disabled: false
query-concurrency: 1024
query-initial-memory-bytes: 0
query-max-memory-bytes: 0
query-memory-bytes: 0
query-queue-size: 1024
reporting-disabled: false
secret-store: bolt
session-length: 60
session-renew-disabled: false
sqlite-path: ""
storage-cache-max-memory-size: 1073741824
storage-cache-snapshot-memory-size: 26214400
storage-cache-snapshot-write-cold-duration: 10m0s
storage-compact-full-write-cold-duration: 4h0m0s
storage-compact-throughput-burst: 50331648
storage-max-concurrent-compactions: 0
storage-max-index-log-file-size: 1048576
storage-no-validate-field-size: false
storage-retention-check-interval: 30m0s
storage-series-file-max-concurrent-snapshot-compactions: 0
storage-series-id-set-cache-size: 0
storage-shard-precreator-advance-period: 30m0s
storage-shard-precreator-check-interval: 10m0s
storage-tsm-use-madv-willneed: false
storage-validate-keys: false
storage-wal-fsync-delay: 0s
storage-wal-max-concurrent-writes: 0
storage-wal-max-write-delay: 10m0s
storage-write-timeout: 10s
store: disk
testing-always-allow-setup: false
tls-cert: "/etc/ssl/influxdb-selfsigned.crt"
tls-key: "/etc/ssl/influxdb-selfsigned.key"
tls-min-version: "1.2"
tls-strict-ciphers: false
tracing-type: ""
ui-disabled: false
vault-addr: ""
vault-cacert: ""
vault-capath: ""
vault-client-cert: ""
vault-client-key: ""
vault-client-timeout: 0s
vault-max-retries: 0
vault-skip-verify: false
vault-tls-server-name: ""
vault-token: ""
https-enabled: true
https-certificate: "/etc/ssl/influxdb-selfsigned.crt"
https-private-key: "/etc/ssl/influxdb-selfsigned.key"The python client
Having already used the v.1.x python client, and having watched Anais’s presentation on Flux, adapting to the v.2.x version of the client was the easy part. At first I was using the script to write data in text files and then adapted the code to use those data keys as tags and fields for points to be written by the client to influxdbv2. You can look back to the part of the code here below (repeated from earlier)
client = InfluxDBClient(
url=url,
token=token,
org=org,
verify_ssl=False
)
write_api = client.write_api(write_options=SYNCHRONOUS)
timestr = str(time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime()))
for record in final_list:
#p = influxdb_client.Point("mac-address-access-network-attiki").tag("mac-address", record['mac_address']).field("temperature", 25.3)
p = Point("mac-address-access-network"
).tag("switch_address",record["switch_address"]
).tag("switch_name",record["switch_name"]
).tag("port",record["port"]
).tag("mac-address",record['mac_address']
).tag("host_ip",record["host_ip"]
).tag("host_name",record["host_name"]
).tag("vlan",record["vlan"]
).field("switch_location",record["switch_location"]
).time(timestr)
write_api.write(bucket=bucket, org=org, record=p)
client.close()The logic behind forming the points with so many tags was to support a search and group by any of those. There was no need to group by switch location (site) and we need at least one field, so location => field. There may be problems with defining so many tags. I never got any feedback that talked me out of it, actually there was no reference of anyone gathering mac address data and storing it in TSDB of any kind so if there are worries about cardinality, we will have to wait and see. There may be dependent tags there and I will probably have to monitor cardinality to make sure everything is working properly.
So how does it look?
In the InfluxDB GUI, exploring the data collected is very easy. All one needs to do is start the DB, fire up the script and watch the data pour in in the InfluxDB GUI!
Launch the container with this, on the server where you deployed the python code. Needless to say that you will need at least Docker in that host (same instructions as above for installing Docker):
docker build -t <docker image name> -f ./dockerfile.ubuntu .
/usr/bin/docker run --rm <docker image name>If you want the code to run periodically, enter something similar in the crontab. This will run the script every 20 mins by creating an ephemeral container that will run the code and then destroy itself:
2,22,42 * * * * /usr/bin/docker run --rm <docker image name>When the macs start pouring in, the data explorer can help you visualize the results. You can turn the options into a flux querry using the built-in Script Editor.
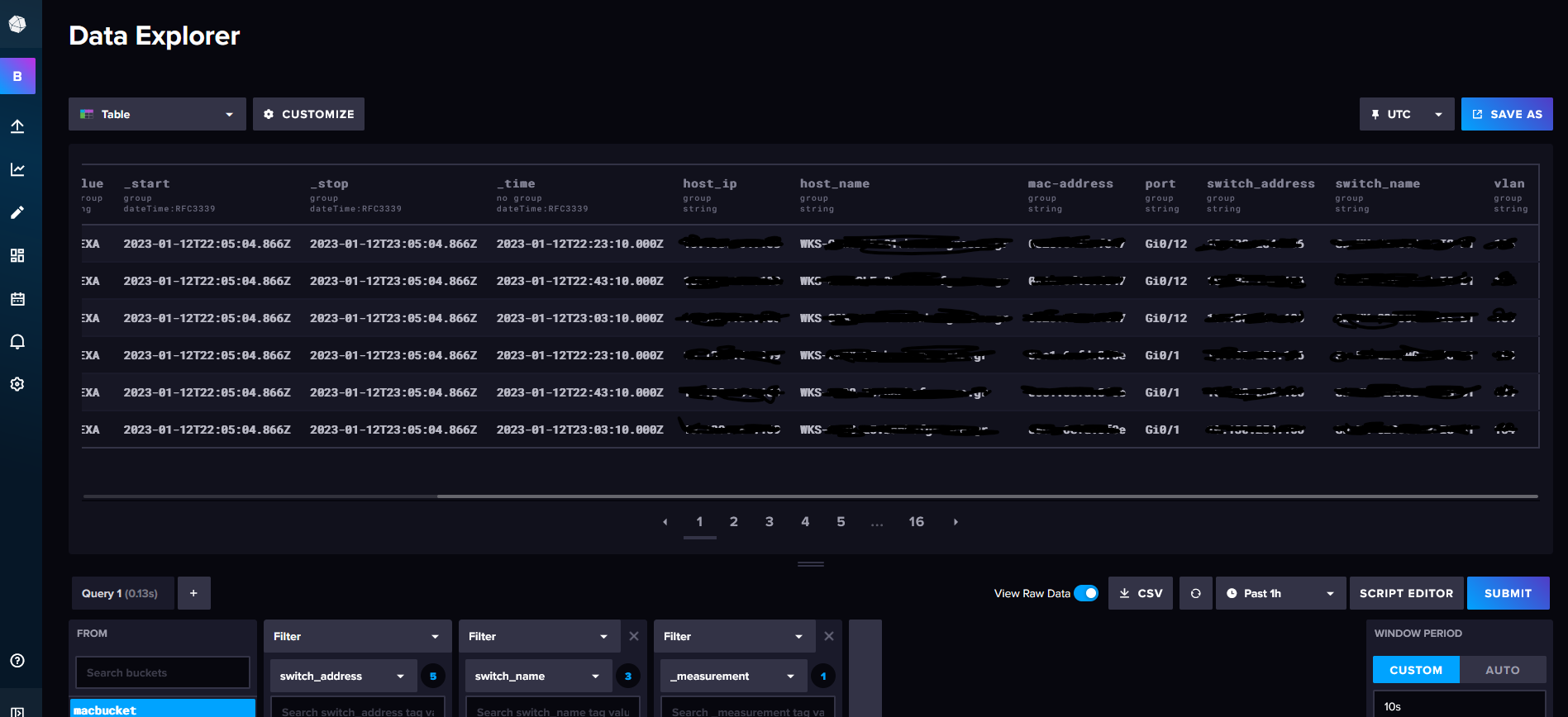
So he is the result of it all, ready to be used either for visualization or for further processing when needed.
What’s next
I have to study Flux a little more to create functional queries that can be parameterized so I can filter and group by swich, port, hostname, mac address, etc.
Those queries should become the basis so that others can access the data through Grafana, where I can control access via other means (AD security groups, AD – Ldap based login).
Luckily I can use InfluxDB University to enrich my understanding for InfluxDB. You can get access to it easily, it’s an online learning website that can offer various courses for free, so that you can learn InfluxDB and the relevant tools that make up its tool-set.
I would also like to explore the capability to querry InfluxDB for data via the python client so I can use the info in Python scripts to follow mac address history and facilitate our migrations for our project.
Epilogue
So this was a blog post describing the path to deploying a custom solution to periodically gather mac address historic data and store it via Python client in your own OSS influxDB deployed on docker.
I hope you enjoyed reading and are tempted to try it out for yourself. If you need to contact me, you can find me under the @mythryll handle on Twitter.